Since 1890 when James Strong published his Exhaustive Concordance of the Bible, people everywhere have used this work for their personal Bible study. By using the concordance, they could look up a verse by any word they remembered in that verse and find its location in the Bible. Before the age of computers, a concordance like the one compiled by Strong was the way to find a verse in the Bible if one had forgotten in which book and chapter the desired verse was to be found.
But that was not all for which Strong’s Exhaustive Concordance was useful. If a person was reading their Bible and wanted to find other verses that contained the same English word as a particular word that had caught their attention, they could look that word up in the concordance (since every English word in the Authorized Version of the Bible was alphabetically listed) and find other verses that utilized that same word. This procedure became a handy tool for finding cross-references to the verse or passage one might be reading or studying.
And there was yet a further component to James Strong’s Exhaustive Concordance. Every Hebrew word (in the Old Testament) and Greek word (in the New Testament) was assigned a number. By looking up the English word, one could find the corresponding Hebrew or Greek number underlying the English word, and by this method could determine whether the same Hebrew and/or Greek word was the original from which the English word had been translated. Since many different English words were used to translated a given Hebrew or Greek word (depending upon the context), this gave the English reader the advantage of knowing if more than one Hebrew or Greek word was represented by a single English word. As an example, consider Genesis 39:6 as compared to Genesis 42:7.
And he left all that he had in Joseph’s hand; and he knew not ought he had, save the bread which he did eat. And Joseph was a goodly person, and well favoured. (Gen 39:6, KJV)
And Joseph saw his brethren, and he knew them, but made himself strange unto them, and spake roughly unto them; and he said unto them, Whence come ye? And they said, From the land of Canaan to buy food. (Gen 42:7, KJV)
In both verses the English word “knew” is found. One might wonder: “Do each of these occurrences translate the same Hebrew word?” Opening up Strong’s Concordance to the word “knew,” and finding each of the verses, one discovers that the number assigned to the word “knew” is different in these two verses. In Gen 39:6 “knew” has the number 3045 while in Gen 42:7 “knew” has the number 5234. Going to the back of the Concordance where the Hebrew and Greek numbering system is laid out in numerical order, one finds that #3045 designates ידַָע (yāda‘) while #5234 designates the Hebrew word נכַָר (nākar). By this method, the reader is alerted to the fact that different Hebrew words lay behind the same English word used by the KJV translators.
Now the question arises in the reader’s mind: “How does the meaning of #3045 differ from the meaning of #5234? Turning to #3045 and #5234 in “A Concise Dictionary of the words in the Hebrew Bible” at the back of Strong’s concordance, one encounters the following entries:

One immediately can see that there are two different Hebrew words which underly the English word “knew” in Gen 39:6 and Gen 42:7 respectively. But the next question one ought to ask is all important: “Where did James Strong derive the meanings he lists for each of the Hebrew words under investigation? The Introduction to the Hebrew word lists, each with its uniquely assigned number, gives the answer. Note paragraph #6.

Note this carefully: the “definitions” given for any particular Hebrew or Greek word listed in the Strong’s “Dictionary” are simply all of the English words chosen by the King James Version translators for that particular word. Thus, Strong’s “Dictionary” is not actually a dictionary at all, and clearly not a Lexicon, but rather a listing of the words which the translators of the King James Version deemed appropriate.
While the translators of the King James Version were clearly top scholars of their day, and surely accomplished a significant benchmark for English translations of the Bible, their choice of English words to translate the original Hebrew, Aramaic, and Greek of the Bible were just that: a translator’s choice, which does not constitute a valid “Dictionary” and most certainly not a “Lexicon.” Moreover, the advancements in Hebrew, Aramaic, and Greek lexicography since 1611 are enormous, not to speak of the discoveries which revealed historical facts from the ancient world unknown in the 17th Century. Consider the fact that the Rosetta Stone, which was discovered in 1799, was the key which enabled scholars to decipher Egyptian hieroglyphs and unlock the ancient Egyptian language previously unknown. Add to this the discovery of Ugaritic at modern day Ras Shamra in Syria, a Northwest Semitic language which enabled scholars to read an early Semitic language which represents an early stage of the Hebrew language in which the Tanach (Old Testament) is written. This opened up major vistas of understanding, not only in terms of lexicography (how various words found in the Hebrew Bible were used in ancient times) but also in grammar and syntax of biblical Hebrew. And consider that perhaps one of the most significant discoveries for the study of the Tanach (Old Testament) was the Dead Sea Scrolls, discovered between 1946 and 1956.
So even though the KJV translators were top scholars of their day, to rely upon a list of English words used to translate the Bible over 400 years ago is to consider all of the advancements made in the study of biblical Hebrew, Aramaic, and Greek as of no real value.
Here is one example of a lexical discovery unknown by the KJV translators. In Gen 18:2 we read:
And he lift up his eyes and looked, and, lo, three men stood by him: and when he saw them, he ran to meet them from the tent door, and bowed himself toward the ground… (Gen 18:2)
If one were interested in discovering the Hebrew which is translated “bowed himself” by utilizing Strong’s Concordance, one would go to the word “bowed” in the concordance and find Gen 18:2 (which is the first entry), and see that it has the corresponding number 7812. Looking in the back of the concordance at the “Hebrew Dictionary,” and finding #7812, one would be informed that the Hebrew word translated “bowed himself” is שָׁחָה (shâchâh). But this is wrong, not because Strong made a mistake, but because until the NW Semitic language of Ugaritic was discovered, no one knew that this particular Hebrew word is the only “hishtafel” form in biblical Hebrew, and its root is not shâchâh but is חָוָה (châvâh).
Of course, in our modern world and with computer technology, Strong’s numbers have been collated with the biblical text and even with a Hebrew lexicon such as the one edited by Brown, Driver, and Briggs as well as Greek lexicons such as the one edited by Thayer. And other word-study books and software programs have utilized Strong’s numbers as a convenient cross-reference for people who cannot work in the original languages themselves. This, admittedly, is a significant advancement over simply using the bulky printed version of Strong’s Exhaustive Concordance.<
So what is the major drawback when using Strong’s numbers to discover the author’s meaning in a given verse of Scripture? It is this: Strong’s numbers tell you how the KJV translators might have translated a given word in the text in 1611. These numbers do not give you the semantic range of a given word but only the English words the KJV translators chose when they made their translation. To think that the KJV translators were the final authority in Hebrew, Aramaic, and Greek lexicography is, unfortunately, to put one’s head in the sand and to ignore real and substantial advancements in understanding the biblical languages.
But there is one further pitfall that looms in the path of those who think they can use Strong’s numbers to discover the author’s meaning in any given text of the Bible. And this pitfall is that very often, people who use Strong’s numbers fall prey to the notion that words, in and of themselves, have meaning. The truth is that words have a semantic range of meaning, but only the immediate context in which a word is found can give the necessary criteria to know which of the meanings within a word’s semantic range is that which the author intends.
Let’s use the English word “just” as an example of “semantic range.” In the circle below, all of the various shades of meaning attached to the word “just” in the English language, as noted in Webster’s Dictionary, are given. Then on the side margins, I’ve appended short sentences using the word “just” in its various meanings.
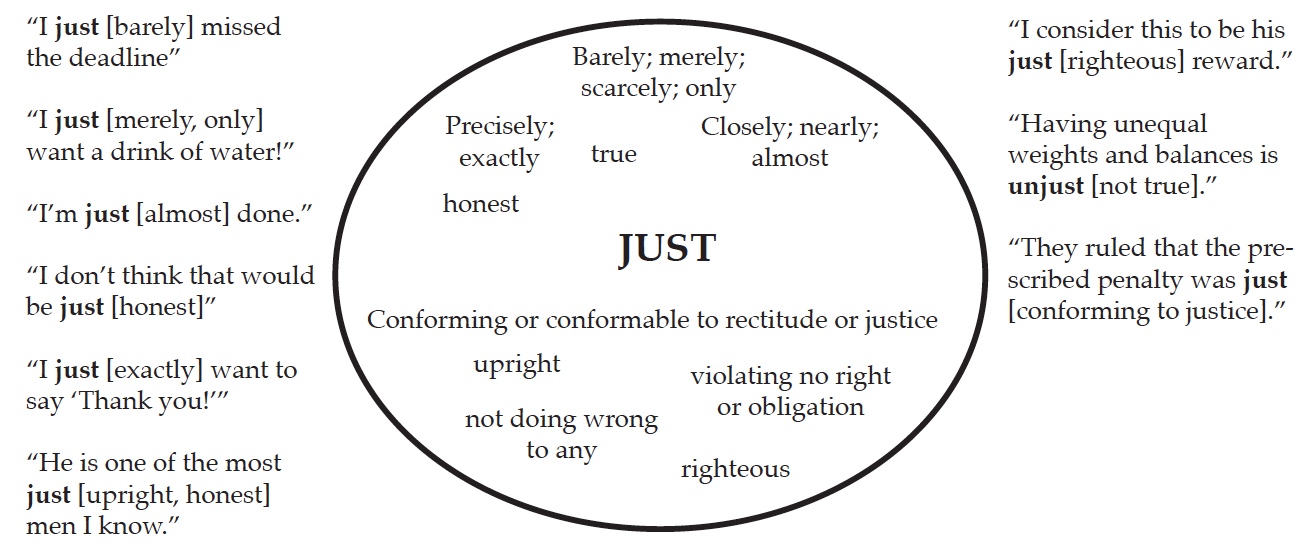
Now consider the semantic range of the English word “just,” as given in the circle above. If you were a non-English speaker, and found the word “just” in a sentence you were attempting to understand, you might open an English Dictionary, find the word “just,” and note the circle of meanings (the word’s semantic range) given there. If you arbitrarily choose one of those meanings which you like, or which makes sense to you and import it into the sentence you are seeking to translate, there is a very good possibility that you will have chosen a meaning the author never intended. This is because a word gains its meaning by context, not by being chosen from a list expressing the semantic range of the word. Moreover, the meaning of a given word or group of words in any particular text of Scripture must be read in light of the larger context as well as the immediate context. The current “theme” of the author may control the particular meaning of a word or words in the text being read, and this theme may span a larger portion of the text, not just a few surrounding verses.
In summary, the use of Strong’s numbers as a means for interpreting the Scriptures is fraught with a number of pitfalls.
But no language works that way, whether ancient or modern. Words gain their meaning by the context in which they are used (as noted by the sentences accompanying the “semantic range” of the English word “just,” given above). Thus, any list of “word meanings” can only attempt to give the semantic range of meaning for a given word or group of words. It is the context that must determine which meaning within the semantic range of a word is what the author intends. Therefore, to find two verses that both use the same word, and presume that the meaning for that word is therefore the same in both verses, is the very pitfall into which many have fallen. Unfortunately, there are also teachers who have founded their teachings on just such an errant method. Even worse, many who follow such teachers are sure they are right and point to the fact that “the same word is used in both verses” as their anchored proof.
But this short study is not designed to discourage the study of God’s word, the Bible! My purpose is to encourage more reading and study of the Bible, but to do so by utilizing methods that will bring forth the biblical author’s intended meaning as the text is read. Therefore, using a Dictionary of biblical terms, or a Lexicon (if one is able to read the biblical languages) is a great tool, and even better if the Dictionary or Lexicon is on one’s computer, meaning it is updated to some extent. But as you use such word lists, word studies, dictionaries, or lexicons, don’t fall into the trap of concluding that if two verses “use the same word,” that the author(s) intended meaning is the same in both of them. Context determines word meaning in a literary context. Dictionaries and lexicons only provide the semantic range of the word, and some do this better than others.
